Text2SQL 不重要,企业数据流真正要改的是这三件事¶
前两天我一个做运营的朋友,在群里突然 @ 我。
问我,哥们,你们那个系统能不能看一下上周广东新客占比。
我说可以啊,直接问 AI 助手就行。
他沉默了一会儿,回了我一句,你们居然已经做到这种程度了吗。
我当时就愣了一下。
不是因为他问得多难,而是我突然意识到,这么小一件事,在他们公司,大概率还要走一圈「我找我们数据的老哥 → 老哥排期 → 老哥写 SQL → 跑一下 → 截个图发给我」的流程。
他那句话的语气里,有一点羡慕,也有一点无奈。
我一直觉得,企业内部的数据流转,是这个时代被严重低估的一块肉。
你去任何一个还没被 AI 卷过的公司,随便抓一个运营、产品、销售,问他「你要一个数,大概要多久」。他给你的答案,通常是「看人」——看数据同学今天忙不忙,看这个需求排在他第几个。
这件事,在 2026 年了,真的还要这样吗?
坦率地讲,我一直觉得,这是 LLM 这一波浪里,最值得扑上去做的场景之一。
你想想看,这些年所谓的「数据驱动」「BI 化」,落到每个普通员工手里是什么。是一张被锁死的看板,维度就那几个,筛选就那几个,想看点不一样的,对不起,找数据同学排期。说到底,我们只是把「找 IT 要报表」变成了「找数据要看板」,瓶颈一点都没消失。
Quote
真正的卡点,从来就不是 SQL,是那个站在业务和数据中间的人。
所以我们现在聊 Text2SQL,聊 Chat BI,真正要改的,不是「让 AI 替谁写 SQL」这么个小事,而是「把业务人员和数据之间那几层墙,全部拆了」。
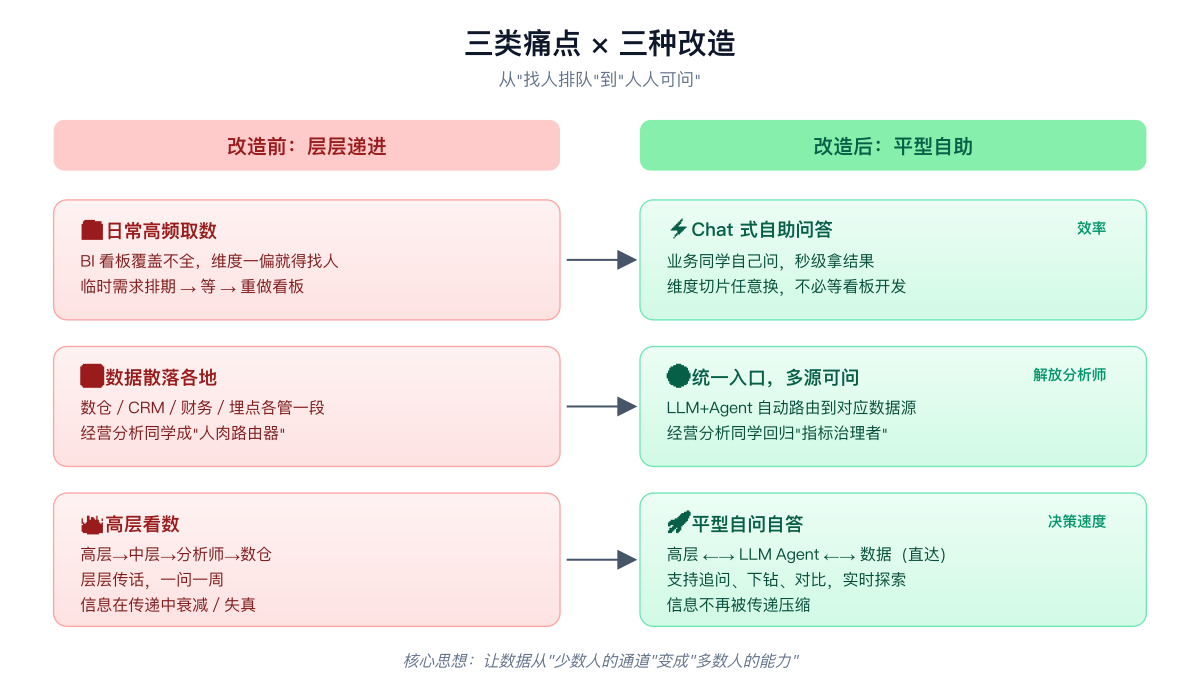
具体来说,大概是三件事。
第一件,日常常规取数效率¶
一个团队每天要看的数,翻来覆去就那些,昨天销售额、本周新客、某业务线达成率。这种东西,按理说,任何一个普通员工自己就应该能拿。但现实是,BI 看板做得再漂亮,维度一旦偏一点点,立刻就不行了。想多加一个地区筛选,要开发。想换一个时间窗口,要改看板。想看一个历史看板上没有的切片,对不起,提个需求,下周见。
这不是效率问题,这是一种极其系统性的浪费。
第二件,数据散落的问题¶
你去看任何一个经营分析团队,同事们真正在做的事,很大一部分不是「分析」,是「取数」。运营要渠道数据,产品要功能数据,销售要客户数据,财务要成本数据。这些数据散在数仓、CRM、财务系统、埋点里,而所有人都只知道找你一个人。
你就成了全公司的人肉路由器。
这种活特别消耗人。每一个有点追求的经营分析同学,都不想干,但每一个都在干。
第三件,是我最想聊的——高层看数¶
传统的企业里,高层想问一个问题,链路长得离谱:
高层 → 中层 → 经营分析 → 取数 → 汇总 → 层层递进汇报回来
每一层都在做翻译,每一层都在加工,每一层都有信息衰减。更可怕的是,一个来回下来,一周就过去了。决策窗口早没了。
你想想看,这不就是赛博版的《北京折叠》吗。数据明明都在那台服务器上,但信息在向上传递的过程中,被一层层折叠、一层层包装、一层层筛选。最后送到决策者桌上的,已经不是数据本身了,是经过几道手之后的「解读」。
AI 时代最让我兴奋的一个可能性,就是这层结构可以被彻底拍平。
高层直接对着系统问。系统直接给答案、给图、给解读。有追问继续问。整个链路,从层层递进,变成了一个平面。
让公司里每一个想问问题的人,都能直接拿到答案——这才是 LLM 真正要解决的企业问题。
为什么是现在¶
好,聊完了「改什么」,聊聊「为什么是现在」。
这件事过去这些年不是没人想做过,2018 年 Spider 数据集一出来,学术圈就在卷 NL2SQL 了。但那个年代的效果,说实话,只能演示。一旦放到企业真实的、上千列、多方言、还带着一堆脏数据的数仓里,立刻就原形毕露。
转折点,其实就是这一两年。有三条线,在同一时间成熟了。
第一条:模型下限被拉起来了¶
GPT、Claude、DeepSeek、Qwen 这几家的头部模型,在 Spider 1.0 这种经典基准上,零样本就能打到相当高的执行准确率。注意,是零样本。啥也不训练,API 调起来,就能达到以前一个算法团队攻坚半年才能到的效果。
第二条:基准升级了¶
业内开始用 Spider 2.0、BIRD、BIRD-Interact 这种真正贴近企业场景的基准来评测。结果会怎样呢?同样一批头部模型,在 Spider 1.0 上能做到八九成,一放到 Spider 2.0,准确率直接断崖式下跌,掉到一成左右。
???
这个数据我第一次看到的时候是懵的。两个都叫 Text2SQL 的基准,差距能有几十个点。
但后来一想也合理。Spider 1.0 是偏学术的测试集,覆盖 200 个数据库、跨 138 个领域,但每个库就几张表、几十列,更像"实验室里的 SQL 模拟题"。Spider 2.0 不一样,它直接从企业真实场景(Snowflake、BigQuery)里挖问题,一个库就有上千列,SQL 动不动就上百行。这才是真实世界。
第三条:工程范式成型了¶
过去这两年,无论是蚂蚁的 Agentar-SQL、阿里的 XiYan-SQL、阿里云的 OpenSearch-SQL,还是 Snowflake 的 Arctic Text2SQL,大家的 Agent Pipeline 长得几乎一样:
意图层 → 语义层 → Schema Linking → SQL 生成 → 反思 → 结果解读 → 反馈闭环
几年前还是「百家争鸣」,现在已经变成了「行业共识」。
三条线在同一时间收敛。我真的觉得,这是企业现在该扑上去做这件事的窗口期。再晚一年,你会发现你的同行都做完了。

不过我得先泼一盆冷水¶
三条线成熟了,不代表这件事能「开箱即用」。让 LLM 对着你的数据库裸写 SQL,准确度是灾难级的。
幻觉会让它编字段、编 JOIN 条件、编函数名。同一个问题问两次,它给你两条不同的 SQL——这不是幻觉,是 LLM 本身的不确定性。还有一种更隐蔽的,语法全对,查出来的数也"看起来挺像",但业务口径其实是错的——这叫业务理解缺失,你一眼都看不出来。
而且,模型侧只是一半。
另一半麻烦在数据侧。你一旦脱离了传统 BI 那套预聚合报表体系,就要直接撞上一堆以前看板时代根本不用想的问题。
一个是计算时效。用户等的是「秒回」,但一条 SQL 在 ClickHouse 上可能几秒,在 Hive 上可能要十几分钟;就算引擎选对,SQL 写得好和写得差,耗时也能差十几倍。往下挖一层你会发现,这根本不是 Text2SQL 自己的问题,而是数据仓库建设那些陈年老账——分区有没有做、索引建得对不对、物化视图有没有命中。Text2SQL 没创造新问题,它只是把数仓的老伤疤一次次撕开。
另一个是数据新鲜性。举个最要命的例子:
Warning
用户上午 8 点问「昨天 CDN 流量是多少」,但 CDN 的数据源,可能要到 9 点才全部到位。系统不报错,也不提示,它就真的给你一个「不完整但能跑」的结果。
这才是 Chat BI 最可怕的失败模式——看起来一切正常,实则错得没人能发现。
这些坑,后面的文章里会一篇一篇掰开讲。这一篇先把话撂在这里。
可以站在谁的肩膀上¶
聊完了「为什么做」,聊聊可以站在谁的肩膀上。
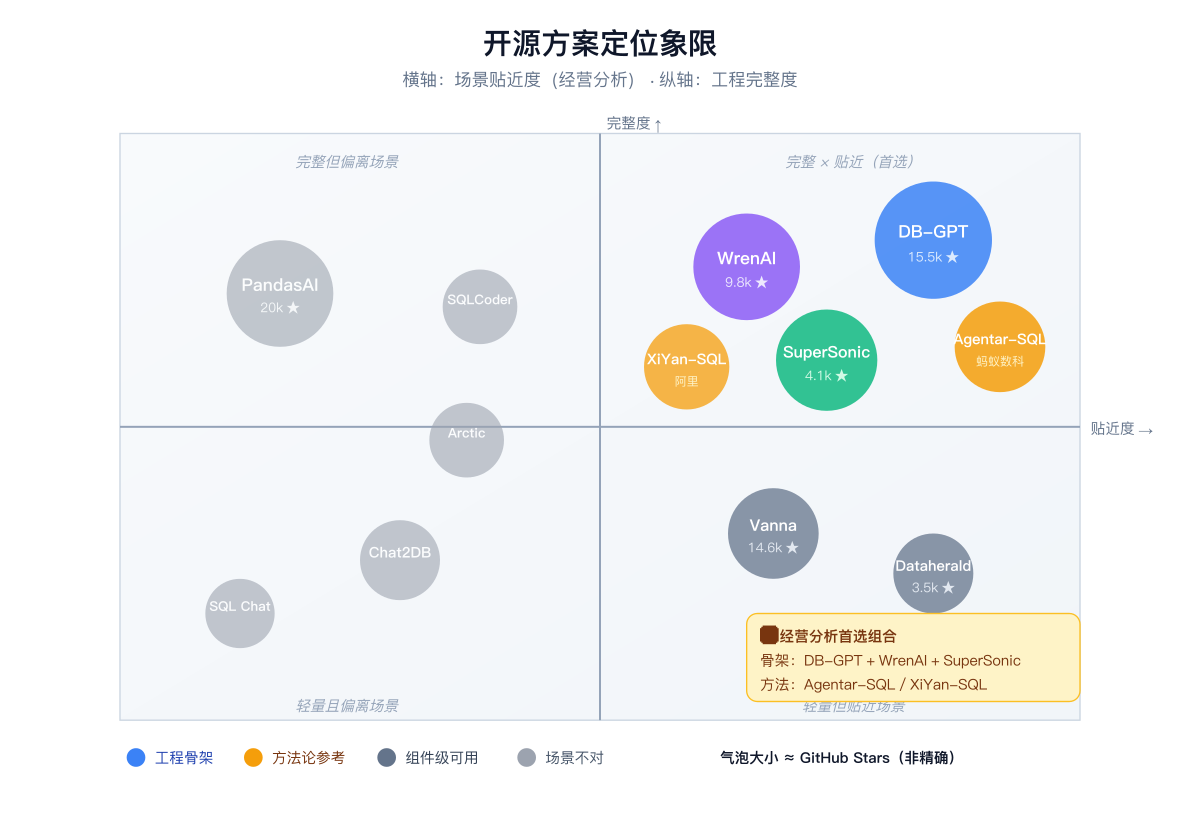
开源世界里关于 Text2SQL 的项目,GitHub 上能搜出 100 多个。但真正贴近「企业经营分析」这个场景的,说实话没那么多。我按贴近度,从远到近,给你过一遍。
先说最远的。PandasAI,star 数在这条赛道里算顶流的,听起来很吓人。但打开看一下就知道,它本质是个 DataFrame 工具,更适合数据工程师在 notebook 里做即席分析。你要拿它去接一个上千列、带语义层、带权限控制的企业数仓,它不是为这个场景设计的。
再近一点的,SQLCoder、Arctic Text2SQL 这些,是纯模型。它们很强,榜单成绩很好看,但拿到它只能当一个零件用,外面还得自己套一整套 Pipeline。对想「开箱即用」的团队,它们不是答案。
往里走,Chat2DB、SQL Chat 这种。它们很好用,但定位是 AI-DBA 客户端,是给开发者用的,不是给业务用的。
再往里,Vanna、Dataherald 这两个。它们都带着企业级 NL2SQL 的基因,尤其是 Dataherald 的「问题 → SQL → 反馈」闭环,做得挺扎实。可以作为组件用,但不算完整框架。
真正让我觉得「可以抄」的,是下面这几个:
- SuperSonic,腾讯音乐开源的,Chat BI + Headless BI 的融合。目前最接近「企业内部 BI」落地形态的开源项目。
- WrenAI,主打一个语义层。它把指标治理放到了一等公民的位置上,这个思路,对企业经营分析场景来说是生死线。
- DB-GPT,eosphoros-ai 社区维护的,GitHub 上热度极高,也是目前企业级 Text2SQL 里讨论最多的一个。多数据源、Agent、知识库、AWEL 工作流,该有的都有。参考架构上最完整。
方法论层面,Agentar-SQL 和 XiYan-SQL 这两个必须看。Agentar-SQL 是蚂蚁数科开源的,在 BIRD 榜单上拿过执行准确率和效率的双料第一,整体思路是「意图理解 → 业务理解 → 数据理解」的全链路 Agent。XiYan-SQL 是阿里出的,贡献了 M-Schema 这种半结构化的 schema 表达,处理大规模数仓特别有用。
Tip
如果让我现在从零开始做,骨架上抄 SuperSonic + WrenAI + DB-GPT 这一组,方法论上学 Agentar-SQL 和 XiYan-SQL。这基本就覆盖了当前能抄的作业。
写在开头的几句话¶
回到我那个运营朋友,他那句「你们居然已经做到这种程度了」,一直萦绕在我脑子里。
这件事真的没有大家想的那么远。模型准备好了,工程范式准备好了,开源项目也准备好了。剩下的,是每一家公司自己愿不愿意扑上去,把那几层墙亲手拆了。
Text2SQL 本身并不重要,重要的是它背后改变的那三件事:
- 日常取数不再卡脖子
- 散落数据有了统一入口
- 决策链路从递进变平型
这三件事加起来,降低的不是几十分钟的等待,而是「愿不愿意多问一个问题」的心理门槛。一旦这个门槛降下来,整个公司的数据文化,会悄悄发生化学反应。
Quote
LLM + Agent 只是手段。真正的目标是,让问题直接找到答案,而不是让流程压制问题。
这是一个系列的第一篇,我想先把地基铺清楚。后面每一个环节,我都想再跟你们仔细聊一聊。
到时候再见。
如果这篇对你有用,转给身边那个「卡在找数据」的朋友。